쿠버네티스 모니터링에서 중요한 담당을 하고 있는 kube-state-metrics의 스케일아웃에 대해서 얘기해보자 한다.
kube-state-metrics는 쿠버네티스 리소스들의 메타 및 상태정보를 메트릭으로 export해주는 컴포넌트다.
프로메테우스에서는 이 메트릭들을 수집하고, 더불어 cpu/memory 등 실제 다른 메트릭과 룰을 통해 새로운 메트릭을 생성한다.
예를 들어 파드 상태 및 재시작/재시작 이유 등을 알수 있으며, 노드 또는 파드의 자원정보를 IP가 아닌 이름으로 표시해줄수도 있다.
kube-state-metrics는 보통 Deployment 1개로만 배포되기 때문에 노드 또는 파드가 많이 늘어났을때 성능을 뒷받침하기 위해 스케일업을 하게 된다. 필요한 경우 노드 크기에 따른 auto scaler를 사이드카로 붙여서 자동으로 스케일업을 할수도 있다.
여기에서 얘기하고자 하는 것은 kube-state-metrics 공식 README에 언급된 Horizontal Sharding 에 대한 이야기이다.
Horizontal Sharding(scale-out)을 지원하기 위해 kube-state-metrics는 수집대상 리소스의 Object ID의 md5 sum을 모듈러 연산하여 정해진 인덱스(모듈러 값)에 해당될 경우만 수집하도록 할 수 있다.
kube-state-metrics는 Horizontal Sharding을 위해 Deployment 외에도 Statefulset 혹은 Deamonset으로도 배포가 가능하다고하는데, 다음과 같은 장단점을 가지고 있다.
Deployment
| --shard={인덱스} --total-shards={만들 총 replica 개수} |
위 옵션을 설정함으로써 Deployment를 이용해 scale-out을 지원할수 있다. 다만 인덱스를 일일히 다르게 작성해줘야하기 때문에 여러개의 Deployment를 만들어야하는 번거로움이 있어 실질적으로 사용하기가 어렵다.
Statefulset
실질적으로 sharding에 사용할수 있는 워크로드 타입이다.
위에 언급한 옵션을 설정할 필요는 없고 다만 다른 두개의 옵션을 설정해야한다.
| --pod={파드이름} --pod-namespace={파드가 속한 네임스페이스} |
위 값의 설정은 메타데이터 정보를 환경변수로 가져올수 있으므로 수동으로 설정할 필요는 없다.
https://github.com/kubernetes/kube-state-metrics/tree/main/examples/autosharding
다음 이 워크로드 타입은 experimental 이라서 향후 변경될수 있다고 한다.
위 두개의 방식은 kube-state-metric Helm chart에서 지원하고 있다. values에서 다음을 수정하면 바로 사용할 수 있다.
https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-state-metrics
| autosharding: enabled: true replicas: 2 |
사실 위 두개 타입은 실질적으로 샤딩을 정확히 지원하는게 아니다. 그 이유는 kube-state-metrics가 데이터를 모으기 위해서 쿠버네티스 API서버에 요청을 하게 되는데 여기서 샤딩이 일어나지 않고 원래대로 100% 데이터를 받기 때문이다. (물론 샤딩 인덱스에 맞지 않는 리소스는 저장을 하지 않기 때문에 메모리 측면에서는 샤딩이 되는건 맞다)
그러니까 kube-state-metrics를 N개 만큼 늘리면, 쿠버네티스 API가 받는 요청개수는 우리가 예상하는 1번이 아닌 N번으로 늘어난다는 점이다. 이것은 쿠버네티스 API가 샤딩을 지원하지 않기 때문이다. 샤딩이 이루어지는 시점은 kube-state-metrics와 프로메테우스간 데이터 이동일때다. 여기서 kube-state-metrics 샤딩의 한계점을 보여준다.
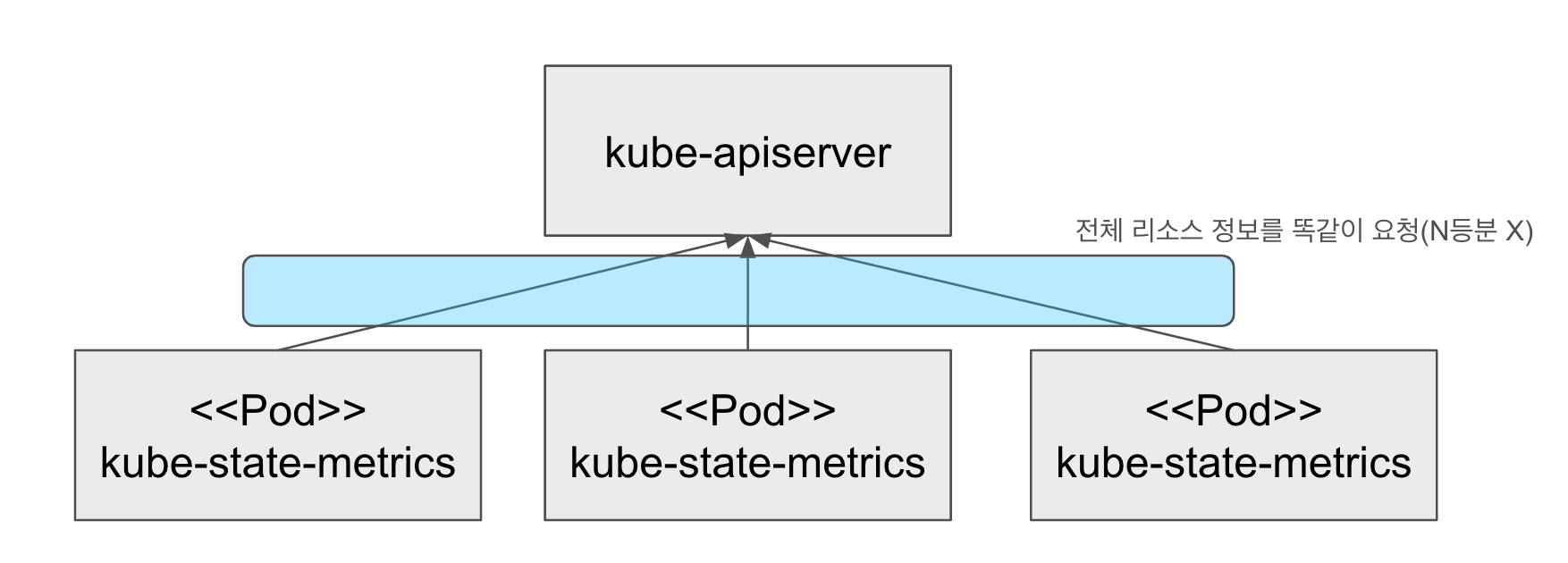
이를 보완하기 위해서 다음의 워크로드 타입도 제안하고 있다.
Daemonset
kube-state-metrics가 생산하는 메트릭의 80~85%정도는 파드에 관한 정보이다. 그렇기 때문에 파드의 정보만 따로 분리하여 별도의 kube-state-metrics 이 각 노드별로 모으면 실질적인 샤딩에 가장 가깝게 된다.
이는 쿠버네티스 API서버가 파드가 배포되어있는 노드필드 정보를 가지고 필터링을 지원하기 때문에 가능한 방법이다.
다음과 같은 옵션을 넣어서 Daemonset으로 배포한다.
| --resource=pods --node=$(NODE_NAME) |
resource 옵션은 어떤 리소스의 메트릭을 모을건지 정하는 옵션인데, 파드정보만 모은다는 뜻이다.
node 옵션은 위에서 언급한 노드필드 기반 필터링 값이다.
헌데, 아직 노드배정이 안된 파드 정보인 경우도 수집이 필요한데 이를 위해서는 다음 옵션을 가진 별도의 Deployment 를 추가로 배포해야 한다.
| --resource=pods --node="" |
물론 위 2개 외에, 다른 리소스를 수집하는 Deployment 또한 해줘야 한다. 그래서 총 3개의 워크로드를 배포해야한다.
3가지 워크로드타입을 알아보았는데, 그럼 Deamonset으로 하는게 맞는가 를 생각해봐야한다.
필자가 확인해봤을때 노드가 5백개 이상, 파드가 5천개 이상이 되어도 특별히 kube-state-metrics에 많은 부하가 가지 않았다.
(150Mi 정도의 메모리를 유지했고, cpu도 0.05 정도만을 유지했다)
실제 API서버에 부하보다 프로메테우스에서 kube-state-metrics의 메트릭 데이터를 스크랩할때 timeout이 나는 이슈를 가장 고려해야한다는 점이다.
그렇기 때문에 굳이 샤딩을 하고 싶다면 Statefulset정도로 2~3개의 파드면 충분하지 않을까 한다. Daemonset방식은 노드 개수별로 파드가 생성되기 때문에 많은 kube-state-metrics 파드가 생성된다.
추가적으로 쿠버네티스 API 서버와의 연결성능을 올리고 싶다면 다음 옵션을 주면 된다고 한다.
--use-apiserver-cache
이 옵션이 어떤 역할을 하는지 코드를 살펴보면, API 서버에 요청할때 ResourceVersion을 0으로 셋팅하는걸 알수 있는데, ResourceVersion을 0으로 명시하면 쿠버네티스 API서버가 가진 내부 캐시에서 가장 최신 리소스 정보를 리턴하게 되어 etcd까지 부하가 가지 않게 된다. 다만 타이밍상 완전히 최신 리소스정보를 가지지 않을수 있기 때문에 메트릭 정보가 부정확할수 있다.
'Development' 카테고리의 다른 글
| nvidia dcgm-exporter(gpu-exporter) (0) | 2024.01.18 |
|---|---|
| 운영 자동화와 최적화 (1) | 2024.01.15 |
| 동적 Prometheus 쿼리 만들기 with golang(레이블 삽입하기) (0) | 2023.12.27 |
| CustomResource Version Converting 과정 분석 (1) | 2021.09.15 |
| Prometheus Query(PromQL) 기본 이해하기 (11) | 2021.04.08 |

